
 April 24, 2026
April 24, 2026
At a Glance: What You Need to Know
- DeepSeek-V4-Flash: 284B total parameters, 13B activated, 1M token context, FP4 + FP8 Mixed precision
- DeepSeek-V4-Pro: 1.6T total parameters, 49B activated, 1M token context, FP4 + FP8 Mixed precision
- Training data: More than 32 trillion high-quality tokens
License: MIT · Tech Report: Available · Models: HuggingFace & ModelScope
The Short Version
DeepSeek-AI just dropped a preview of their V4 series, and it's not an incremental update it's a rethink of how massive context windows should work. Two MoE models: V4-Pro (1.6T total, 49B active) and V4-Flash (284B total, 13B active). Both handle one million tokens natively.
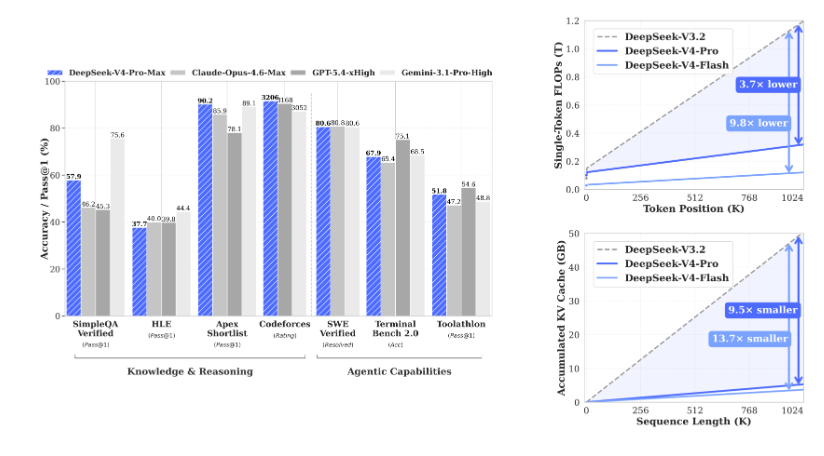
What actually matters: V4-Pro-Max (their highest reasoning effort mode) now holds the top spot among open-source models on Codeforces with 3206 Elo, beats GPT-5.4 and Gemini-3.1-Pro on LiveCodeBench with 93.5% Pass@1, and delivers 80.6% on SWE Verified matching or exceeding most closed-source frontier models.
The efficiency story is just as dramatic. At 1M context, V4-Pro requires only 27% of single-token inference FLOPs and 10% of KV cache compared to V3.2.
Architecture: Three Upgrades Which Actually Change Things
1. Hybrid Attention (CSA + HCA)
DeepSeek moved beyond vanilla attention. They combined Compressed Sparse Attention (CSA) with Heavily Compressed Attention (HCA). The result? At 1M tokens, you're not paying linear costs anymore. Pro's inference FLOPs drop to 27% of V3.2's, and KV cache collapses to 10%.
That's the difference between a model that can do 1M context and one that practically does it without burning your inference budget.
2. Manifold-Constrained Hyper-Connections (mHC)
Residual connections get a major upgrade. mHC stabilizes signal propagation across 1.6T parameters while keeping expressivity intact. No more degradation at depth V4 stays coherent across the full million-token window.
3. Muon Optimizer
They swapped out the usual optimizer for Muon. Faster convergence, more stable training across 32T tokens. That's not a headline feature but it's why the base models are this clean before post-training even starts.
Base Model Benchmarks (No Post-Training)
Raw capability, all base models, no SFT, no RL (leaves room for finetuning)
DeepSeek-V3.2-Base (37B active):
- MMLU: 87.8 | MMLU-Pro: 65.5 | MMLU-Redux: 87.5
- AGIEval: 80.1 | SimpleQA Verified: 28.3 | FACTS Parametric: 27.1
- HumanEval: 62.8 | GSM8K: 91.1 | MATH: 60.5
- LongBench-V2 (1M): 40.2
DeepSeek-V4-Flash-Base (13B active):
- MMLU: 88.7 | MMLU-Pro: 68.3 | MMLU-Redux: 89.4
- AGIEval: 82.6 | SimpleQA Verified: 30.1 | FACTS Parametric: 33.9
- HumanEval: 69.5 | GSM8K: 90.8 | MATH: 57.4
- LongBench-V2 (1M): 44.7
DeepSeek-V4-Pro-Base (49B active):
- MMLU: 90.1 | MMLU-Pro: 73.5 | MMLU-Redux: 90.8
- AGIEval: 83.1 | SimpleQA Verified: 55.2 | FACTS Parametric: 62.6
- HumanEval: 76.8 | GSM8K: 92.6 | MATH: 64.5
- LongBench-V2 (1M): 51.5
Takeaway: V4-Pro-Base is already outperforming V3.2-Base by 2-3 points on most knowledge benchmarks and doubling SimpleQA score. The 13B active Flash-Base is smaller but still beats V3.2 on MMLU and AGIEval. That's the efficiency win.
Instruct Models: Three Reasoning Modes
Both V4-Pro and V4-Flash ship with three reasoning effort levels:
- Non-think: Fast, baseline accuracy. Use for daily tasks and low-risk decisions.
- Think High: Moderate speed, high accuracy. Use for complex problem-solving and planning.
- Think Max: Slow, maximum accuracy. Use for pushing the absolute limit of reasoning.
Think Max requires at least 384K context window locally.
V4-Pro-Max vs. Frontier Models: The Real Fight
This is the section you came for. V4-Pro-Max against Opus 4.6, GPT-5.4 (xHigh), Gemini 3.1 Pro (High), K2.6 Thinking, and GLM-5.1 Thinking.
Coding & Competitive Programming
LiveCodeBench (Pass@1):
- DeepSeek-V4-Pro-Max: 93.5 (leads)
- Gemini 3.1 Pro: 91.7
- Opus 4.6: 88.8
- K2.6 Thinking: 89.6
Codeforces (Rating):
- DeepSeek-V4-Pro-Max: 3206 (open-source best)
- GPT-5.4: 3168
- Gemini 3.1 Pro: 3052
Apex Shortlist (Pass@1):
- DeepSeek-V4-Pro-Max: 90.2
- Gemini 3.1 Pro: 89.1
- Opus 4.6: 85.9
- GPT-5.4: 78.1
V4-Pro-Max leads every major coding benchmark. 3206 Codeforces is open-source best. 93.5% on LiveCodeBench beats Gemini's 91.7%. Apex Shortlist at 90.2% that's the hardest subset.
Knowledge & Reasoning
MMLU-Pro:
- Gemini 3.1 Pro: 91.0
- Opus 4.6: 89.1
- DeepSeek-V4-Pro-Max: 87.5
- GPT-5.4: 87.5
GPQA Diamond:
- Gemini 3.1 Pro: 94.3
- GPT-5.4: 93.0
- Opus 4.6: 91.3
- DeepSeek-V4-Pro-Max: 90.1
SimpleQA Verified:
- Gemini 3.1 Pro: 75.6
- DeepSeek-V4-Pro-Max: 57.9
- Opus 4.6: 46.2
- GPT-5.4: 45.3
Chinese-SimpleQA:
- Gemini 3.1 Pro: 85.9
- DeepSeek-V4-Pro-Max: 84.4
- Opus 4.6: 76.4
- GPT-5.4: 76.8
Gemini holds the MMLU-Pro crown at 91.0, but V4-Pro-Max closes the gap significantly on GPQA (90.1 vs 94.3) and dominates SimpleQA among open-source. Chinese-SimpleQA at 84.4% is effectively tied with Gemini.
Agentic & SWE Benchmarks
SWE Verified (Resolved):
- Opus 4.6: 80.8
- DeepSeek-V4-Pro-Max: 80.6 (tied with Gemini)
- Gemini 3.1 Pro: 80.6
- K2.6 Thinking: 80.2
SWE Multilingual (Resolved):
- Opus 4.6: 77.5
- DeepSeek-V4-Pro-Max: 76.2
- K2.6 Thinking: 76.7
Toolathlon (Pass@1):
- GPT-5.4: 54.6
- DeepSeek-V4-Pro-Max: 51.8
- K2.6 Thinking: 50.0
- Gemini 3.1 Pro: 48.8
- Opus 4.6: 47.2
Terminal Bench 2.0 (Acc):
- GPT-5.4: 75.1
- Gemini 3.1 Pro: 68.5
- DeepSeek-V4-Pro-Max: 67.9
- K2.6 Thinking: 66.7
- Opus 4.6: 65.4
SWE Verified at 80.6% tied with Gemini, within 0.2 of Opus. That's production-grade agentic coding. Toolathlon at 51.8% beats Opus and Gemini. Terminal Bench 2.0 at 67.9% is competitive across the board.
Long Context (1M tokens)
MRCR 1M (MMR):
- Opus 4.6: 92.9
- DeepSeek-V4-Pro-Max: 83.5
- Gemini 3.1 Pro: 76.3
CorpusQA 1M (ACC):
- Opus 4.6: 71.7
- DeepSeek-V4-Pro-Max: 62.0
- Gemini 3.1 Pro: 53.8
Opus still leads MRCR, but V4-Pro-Max at 83.5% beats Gemini by a wide margin. CorpusQA at 62.0% is solidly second. Remember: Pro uses 10% of the KV cache to do this.
V4-Flash vs. V4-Pro: Which One Do You Need?
Here's the comparison across reasoning modes. Flash is smaller (13B active), cheaper, faster. Pro is the heavyweight (49B active).
GPQA Diamond
- Flash Non-Think: 71.2 | Flash High: 87.4 | Flash Max: 88.1
- Pro Non-Think: 72.9 | Pro High: 89.1 | Pro Max: 90.1
LiveCodeBench
- Flash Non-Think: 55.2 | Flash High: 88.4 | Flash Max: 91.6
- Pro Non-Think: 56.8 | Pro High: 89.8 | Pro Max: 93.5
Codeforces (Rating)
- Flash High: 2816 | Flash Max: 3052
- Pro High: 2919 | Pro Max: 3206
SWE Verified
- Flash Non-Think: 73.7 | Flash High: 78.6 | Flash Max: 79.0
- Pro Non-Think: 73.6 | Pro High: 79.4 | Pro Max: 80.6
MRCR 1M (long context)
- Flash Non-Think: 37.5 | Flash High: 76.9 | Flash Max: 78.7
- Pro Non-Think: 44.7 | Pro High: 83.3 | Pro Max: 83.5
SimpleQA Verified
- Flash Non-Think: 23.1 | Flash High: 28.9 | Flash Max: 34.1
- Pro Non-Think: 45.0 | Pro High: 46.2 | Pro Max: 57.9
What this tells you:
- Flash Max (3052 Codeforces, 91.6% LiveCodeBench) is absurdly capable for 13B active params. It beats many closed-source models.
- Pro Max pulls ahead on knowledge (SimpleQA 57.9 vs 34.1) and extreme reasoning (GPQA 90.1 vs 88.1).
- Non-think modes are fast but sacrifice a lot. Don't use them for hard tasks.
Comments